
- The k-Means Method
- k-Medoids Method
- First, it randomly selects k of the objects, each of which initially represents a cluster mean or center.
- For each of the remaining objects, an object is assigned to the cluster to which it is the most similar, based on the distance between the object and the cluster mean
- It then computes the new mean for each cluster.
- This process iterates until the criterion function converges.
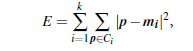
where E is the sum of the square error for all objects in the data set p is the point in space representing a given object mi is the mean of cluster Ci
The k-means partitioning algorithm: The k-means algorithm for partitioning, where each cluster’s center is represented by the mean value of the objects in the cluster.

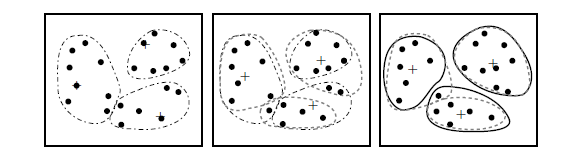
Clustering of a set of objects based on the k-means method
The k-Medoids Method
The k-means algorithm is sensitive to outliers because an object with an extremely large value may substantially distort the distribution of data. This effect is particularly exacerbated due to the use of the square-error function. Instead of taking the mean value of the objects in a cluster as a reference point, we can pick actual objects to represent the clusters, using one representative object per cluster.
Each remaining object is clustered with the representative object to which it is the most similar The partitioning method is then performed based on the principle of minimizing the sum of the dissimilarities between each object and its corresponding reference point. That is, an absolute-error criterion is used, defined as
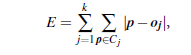
where E is the sum of the absolute error for all objects in the data set p is the point in space representing a given object in cluster Cj oj is the representative object of Cj The initial representative objects are chosen arbitrarily.
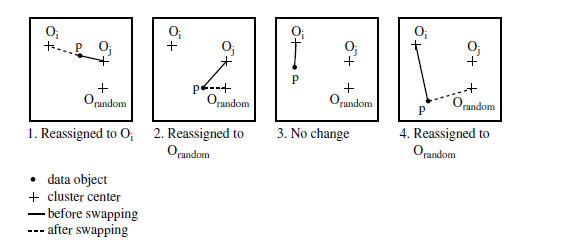
The iterative process of replacing representative objects by non representative objects continues as long as the quality of the resulting clustering is improved. This quality is estimated using a cost function that measures the average dissimilarity between an object and the representative object of its cluster. To determine whether a non representative object, oj random, is a good replacement for a current representative object, oj, the following four cases are examined for each of the non representative objects
Case 1: p currently belongs to representative object, oj. If ojis replaced by orandomasa representative object and p is closest to one of the other
representative objects, oi,i≠j, then p is reassigned to oi.
Case 2: p currently belongs to representative object, oj. If ojis replaced by o random as a representative object and p is closest to o random, then p is reassigned to o random.
Case 3: p currently belongs to representative object, oi, i≠j. If oj is replaced by o random as a representative object and p is still closest to oi, then the assignment does not change.
Case 4: p currently belongs to representative object, oi, i≠j. If ojis replaced by o randomas a representative object and p is closest to o random, then p is reassigned to o random.
The k-Medoids Algorithm: The k-medoids algorithm for partitioning based on medoid or central objects.
