
FIND-S Algorithm
1. Initialize h to the most specific hypothesis in H
2. For each positive training instance x For each attribute constraint ai in h
If the constraint ai is satisfied by x
Then do nothing
Else replace ai in h by the next more general constraint that is satisfied by x
3. Output hypothesis h To illustrate this algorithm, assume the learner is given the sequence of training examples from the EnjoySport task
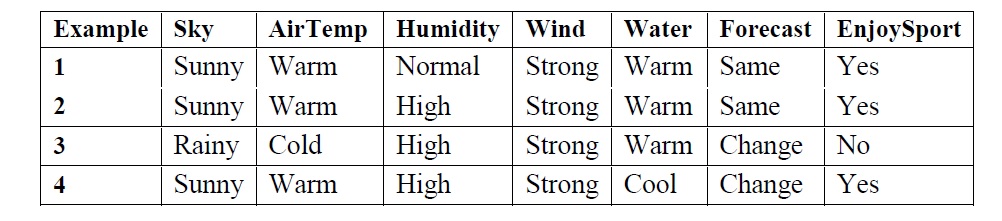
- The first step of FIND-S is to initialize h to the most specific hypothesis in H h – (Ø, Ø, Ø, Ø, Ø, Ø)
Consider the first training example
x1 = , + Observing the first training example, it is clear that hypothesis h is too specific. None of the “Ø” constraints in h are satisfied by this example, so each is replaced by the next more general constraint that fits the example h1 = Consider the second training example x2 = <sunny, warm,=”” high,=”” strong,=”” same=””>, +</sunny,> The second training example forces the algorithm to further generalize h, this time substituting a “?” in place of any attribute value in h that is not satisfied by the new example
h2 =
- Consider the third training example x3 = <rainy, cold,=”” high,=”” strong,=”” warm,=”” change=””>, –</rainy,> Upon encountering the third training the algorithm makes no change to h. The FIND-S algorithm simply ignores every negative example. h3 = < Sunny Warm ? Strong Warm Same>
- Consider the fourth training example
x4 = , + The fourth example leads to a further generalization of h
h4 = < Sunny Warm ? Strong ? ? >
The key property of the FIND-S algorithm
- FIND-S is guaranteed to output the most specific hypothesis within H that is consistent with the positive training examples
- FIND-S algorithm’s final hypothesis will also be consistent with the negative examples provided the correct target concept is contained in H, and provided the training examples are correct.